SRE is not DevOps. It is what keeps your startup reliable as you scale. Learn what Site Reliability Engineering actually means, why startups hit the reliability wall, and the three SRE concepts every founder needs to understand.
Does your team have a written plan for what happens when something breaks at 2am? Most startups do not. That gap is what SRE closes.
What SRE actually means, in plain English
SRE (Site Reliability Engineering) is the discipline of applying software engineering thinking to keeping systems reliable. It was invented at Google in 2003 when the company realised that operating large systems at scale was itself an engineering problem, not just an operations problem.
Google's original SRE brief was simple: hire software engineers to do what sysadmins do, but give them the tools to automate their way out of manual work. For startups, the principle translates directly. Reliability is not a checkbox on a deploy script. It is a set of engineering decisions made before things go wrong.
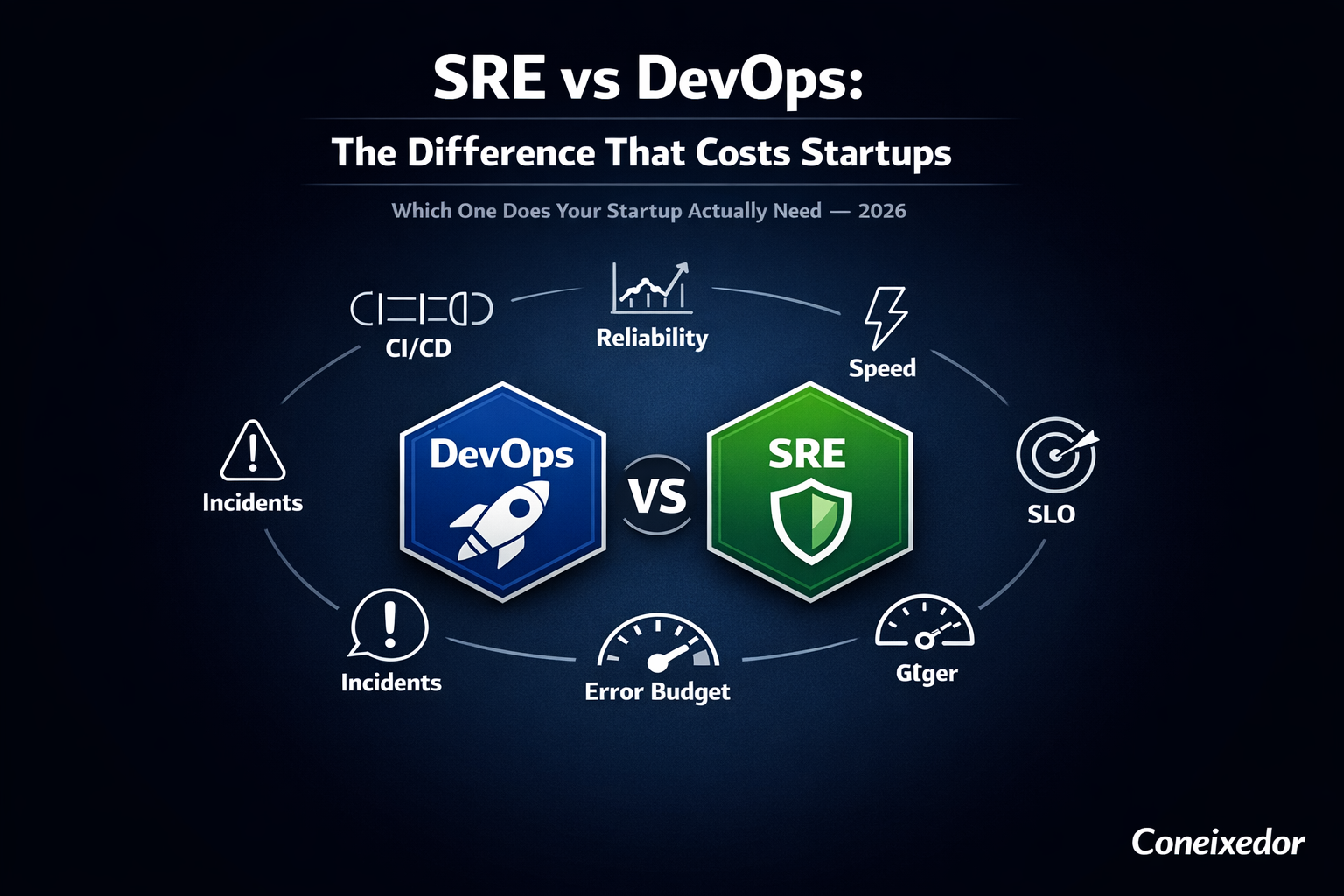
The one question SRE asks that DevOps does not is: what does reliable actually mean for this system? DevOps gives you the pipeline to ship fast. SRE defines the reliability target your pipeline has to meet, and what happens when it does not.
The reliability wall, why startups hit it at exactly the wrong moment
The reliability wall is the moment a fast-moving startup's infrastructure stops keeping up with the product. It almost always hits during a launch, a funding round, or an enterprise deal. The timing is not a coincidence. Growth events send more traffic, attract more scrutiny, and expose every assumption that was fine at a smaller scale.
Infrastructure decisions compound quietly. A database without read replicas is fine at 500 concurrent users and quietly catastrophic at 50,000. A deployment process without automated rollback works until the one Friday afternoon when it does not. These failure modes are not surprises once you know what to look for.
The difference between what looks fine at 1,000 users and what breaks at 100,000 is almost always the same short list: no defined SLOs, no runbooks, no incident process, and no one whose job it is to think about failure before it happens. The good news is that the failure modes are predictable. SRE is the practice of finding them before your users do.
The three SRE concepts every founder needs to understand
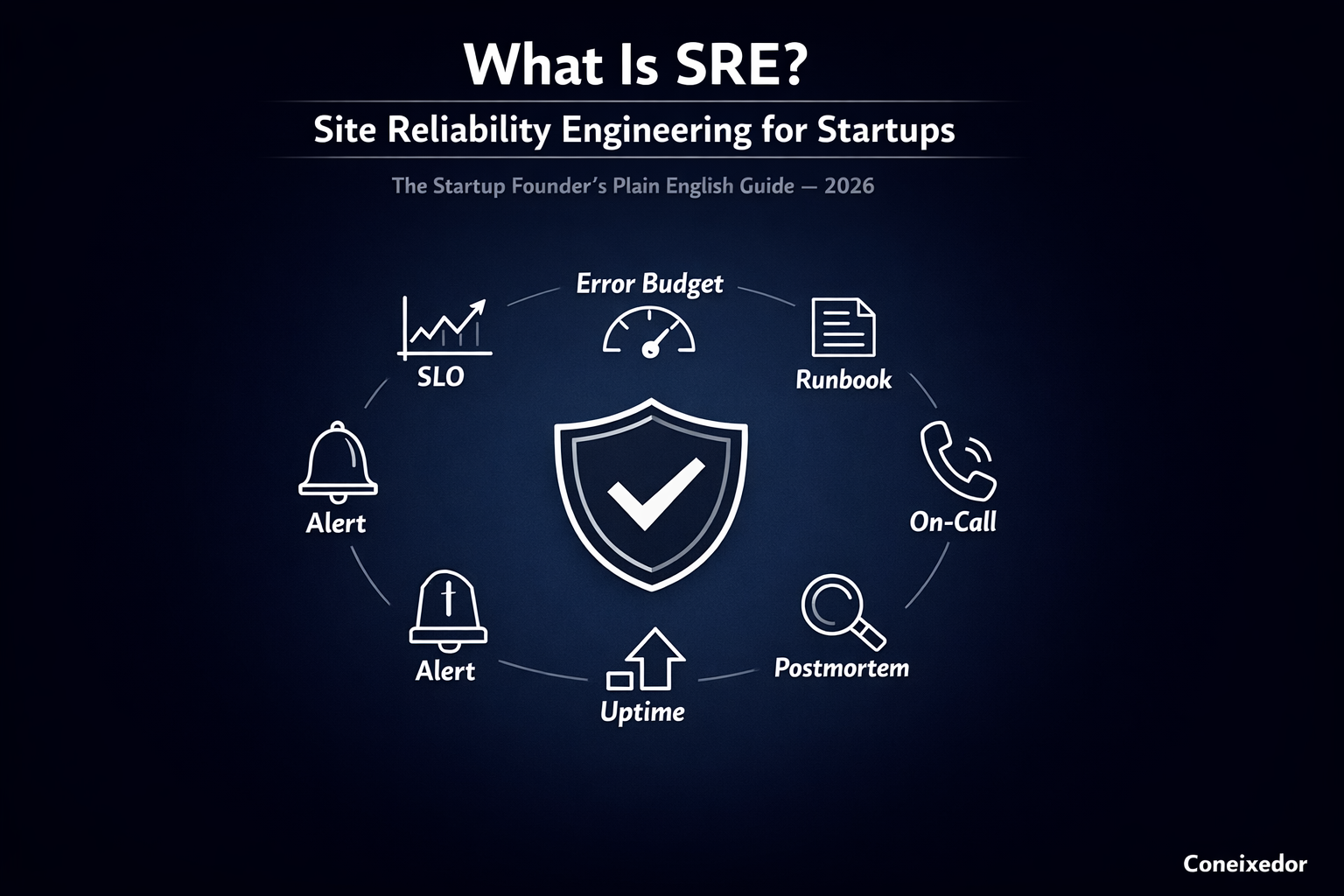
You do not need a 100-person SRE team. You need to understand three concepts: SLOs, error budgets, and runbooks.
An SLO (Service Level Objective) is your specific, measurable promise to users. Not a vague commitment to uptime, but a precise statement: 99.9% of API requests will return a valid response in under 300ms, measured over a rolling 30-day window. Without an SLO, every reliability conversation is a feelings conversation. With one, it is a data conversation.
An error budget is the inverse of your SLO. If you promise 99.9% availability, your error budget is 0.1%, which works out to about 43 minutes of allowable downtime per month. The error budget makes reliability decisions rational. When the budget is healthy, you ship fast. When it is nearly exhausted, you freeze features and fix the foundations. It is one of the most powerful tools in SRE, and almost no startup uses it.
A runbook is the document your on-call engineer reads at 2am when the alert fires. It answers three questions: what is broken, why it might have broken, and exactly what to do about it. A good runbook gets an incident resolved in 15 minutes. No runbook means the resolution time is however long it takes to find the right person and figure it out from scratch.
When does a startup actually need SRE?
The honest threshold: if your product has more than 10,000 active users, you need SRE thinking now, not after your next funding round. Below 10,000 users, basic reliability hygiene is usually enough. Good monitoring, a staging environment, a deployment rollback mechanism, and someone on call are sufficient.
Above 10,000 users, the stakes change. An outage that was embarrassing at small scale is a revenue event and a trust event at large scale. The SRE practices that become essential are defined SLOs per service, runbooks for your top five failure modes, a formal incident response process, and at minimum one person who owns reliability as a primary responsibility.
The most expensive mistake is waiting until after Series A. By that point, you have customers with contractual expectations, engineers who have built habits around a fragile system, and the architectural debt of two years of moving fast without reliability foundations. Rebuilding reliability into a system that was never designed for it costs three to five times what building it in costs.
The startups that invest in SRE thinking before they hit the wall do not just avoid outages. Their engineers stop being afraid of Fridays. On-call shifts become manageable. The team ships faster because reliability is a foundation, not a constant firefight.
If you are not sure whether your infrastructure is ready for your next growth stage, a free infrastructure audit at coneixedor.com will surface the gaps before they become incidents. Fifteen minutes. Founder-direct. No sales pitch.
Frequently Asked Questions
SRE is the practice of applying software engineering principles to keeping systems reliable. It defines what reliable means, measures it with SLOs, and designs systems to fail safely when things go wrong.
A useful threshold is 10,000 active users. Below that, basic reliability hygiene is enough. Above that, you need SLOs, runbooks, and an incident response process.
DevOps optimises for delivery speed. SRE optimises for reliability under that speed. You need both.
An SLO (Service Level Objective) is a specific, measurable reliability target. Example: 99.9% of API requests will return in under 500ms over a rolling 30-day window.
Coneixedor offers a free 15-minute infrastructure audit as a starting point. Engagement costs vary by scope and are discussed after the audit.