SRE · AI-Native · Partner-Led
Every service exists for one reason. To make sure infrastructure never becomes the reason your AI product falls behind.
Whether you are building from scratch, keeping a live product reliable, operating AI workloads in production, or trying to ship faster. Every engagement starts with understanding your specific situation. Not a template. The right practice for where your product is right now.
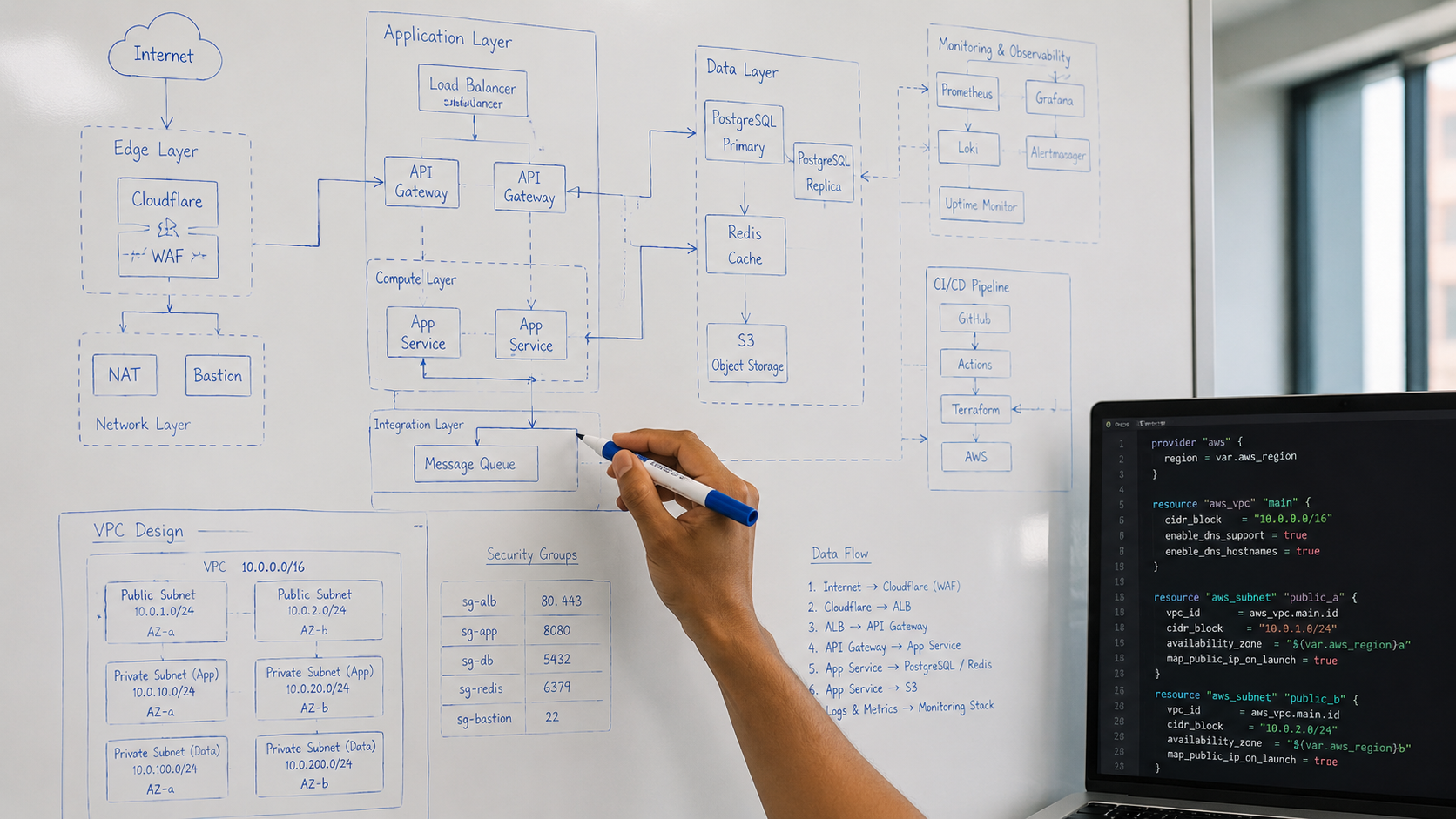
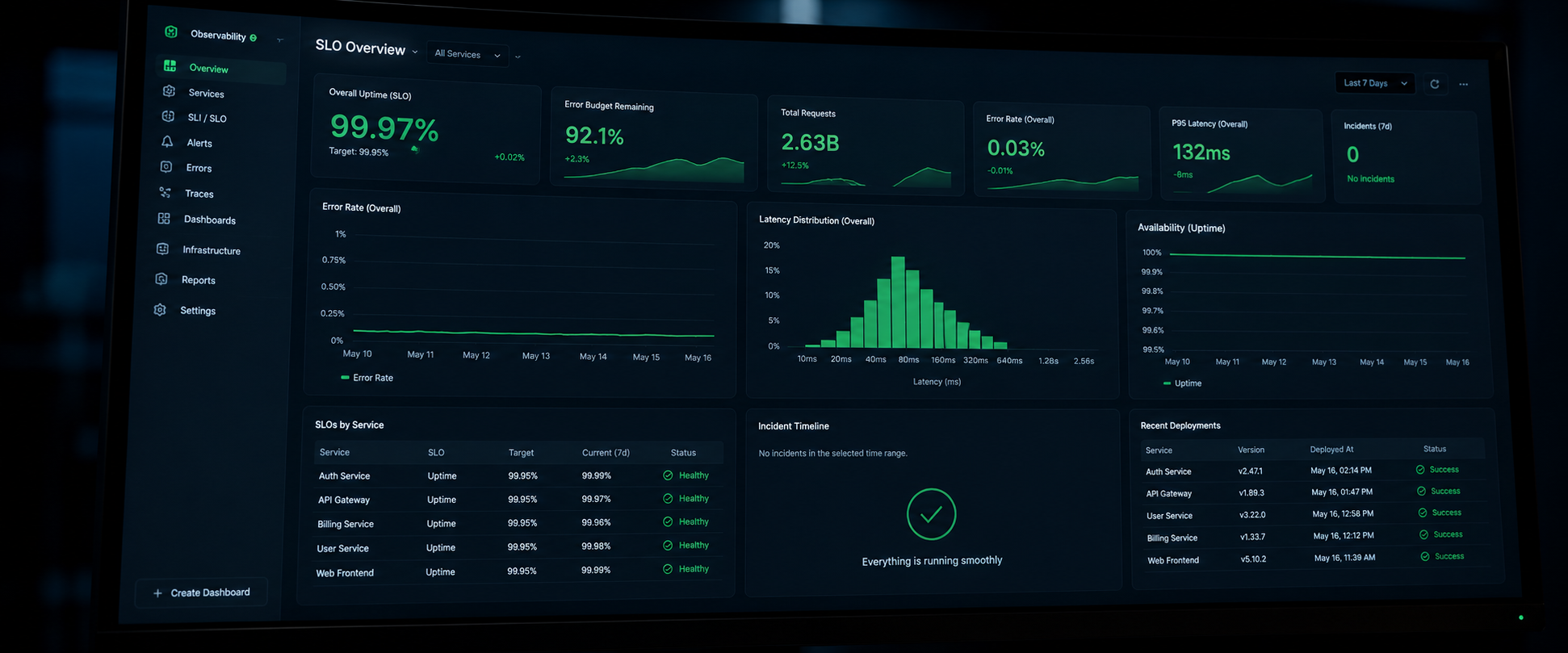
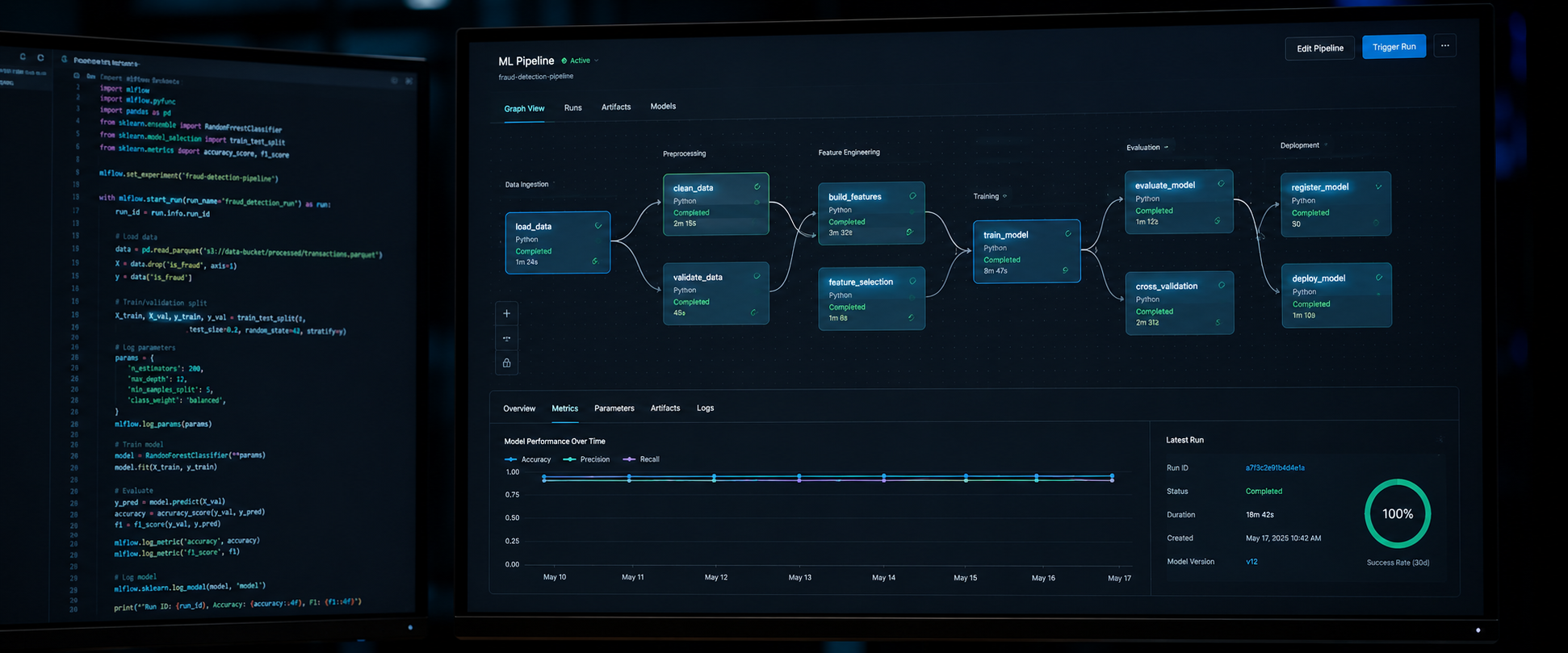

Not sure which group fits your situation? Most founders come in thinking they have one specific problem. The first 30 minutes usually surfaces two or three they did not know existed.
Book a Free Infrastructure Audit30 minutes. Senior partner. No pitch.